
Every InsForge engineer used to run Claude Code on their own laptop. Now every session lives on an EC2 VPS, spawned from a shared AMI, with Claude Code in tmux and a Discord channel pointed at it. Cheaper, safer, easier to control. We are not going back, and we think every engineering team should make the same move.
The Problem With Local Agents
A Claude Code session on a laptop has three problems that compound with team size:
- Productivity. The agent only works while the laptop is awake. Either it stays open overnight, or the agent dies with the lid. Long tasks queue behind whoever is on coffee.
- Trust. A local agent runs as the developer. SSH keys, AWS profile, database password, shell history. The blast radius of a wrong command is whatever that laptop can reach.
- Auditability. Each developer ends up with their own private transcript and their own private incident.
We did look at hosted alternatives. OpenClaw is the closest off the shelf option, but the setup was finicky, the runtime was heavier than we needed, the process died at random, and the security surface was bigger than we wanted to ship. We wanted something we ran ourselves.
The Setup
We bake a custom AMI with Claude Code, tmux, a Discord bridge bot, and a fixed set of MCP connectors preinstalled: GitHub, Notion, our Postgres replica, PostHog (with Stripe as a read only data source), CloudWatch, and AWS (the last two read only). Each engineer spins up their own EC2 from that AMI. One image, N identical machines.
Claude Code lives inside a persistent tmux session, so SSH disconnects and bot redeploys do not kill it. The bridge bot pipes one Discord channel per engineer to that tmux pane. The team can drop in to read along or take over.
The whole shape, top to bottom: Discord channel ↔ Discord bridge bot ↔ Claude Code (in tmux) ↔ MCP connectors, with the agent reaching out through MCP to the systems below.
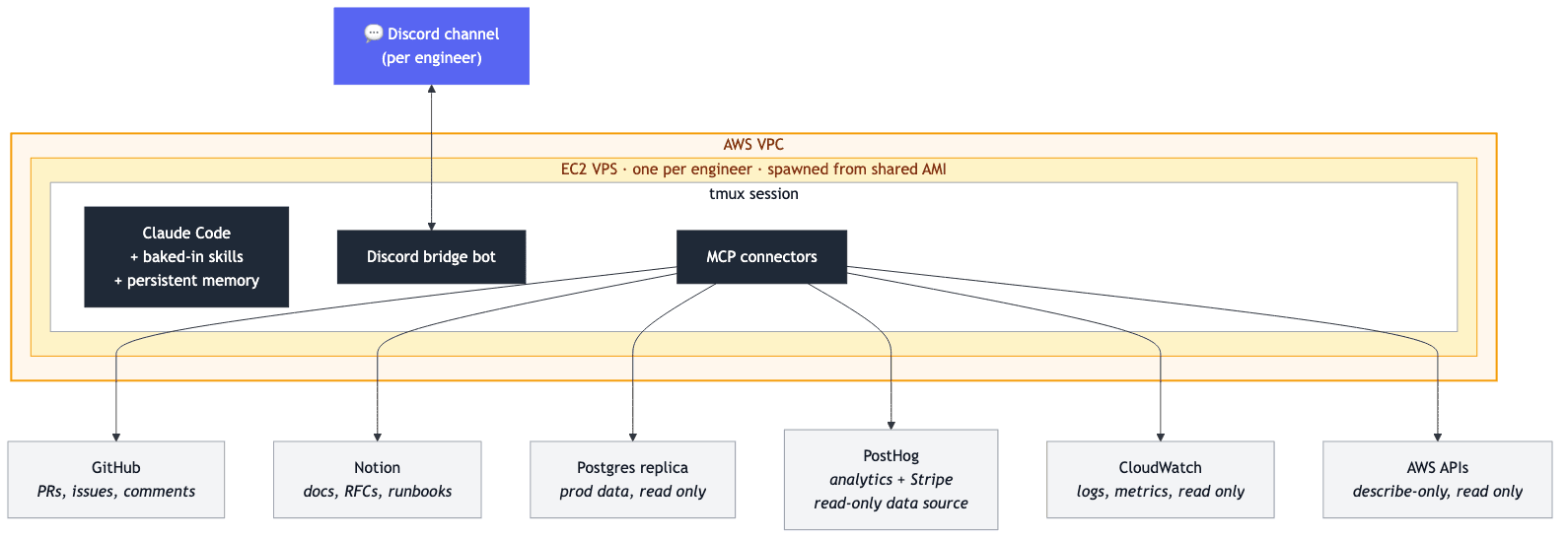
Connectors
Every agent gets the same scoped access to the systems we actually use, baked into the AMI:
- GitHub: read PRs and issues, comment, request review. Branch pushes go through a human.
- Notion: read and write docs, RFCs, runbooks.
- Postgres replica: a read only replica of our prod database. The agent answers business questions against real numbers, with no path to prod writes.
- PostHog: product analytics. Funnels, retention, feature flags.
- Stripe (via PostHog): a read only PostHog data source. The agent answers revenue questions through the same MCP, without ever holding a Stripe key of its own.
- CloudWatch (read only): pull logs and metrics without waking the on call rotation.
- AWS (read only): describe instances, buckets, IAM, billing. Never mutate.
Read only across infrastructure is deliberate. The agent investigates anything, mutates nothing in production.
What It Actually Looks Like
Earlier this week I asked the agent to correlate our AI usage data with churn. It pulled numbers from PostHog, joined them against the subscription state in our Postgres replica, and came back with a single conclusion. Specific figures redacted below:
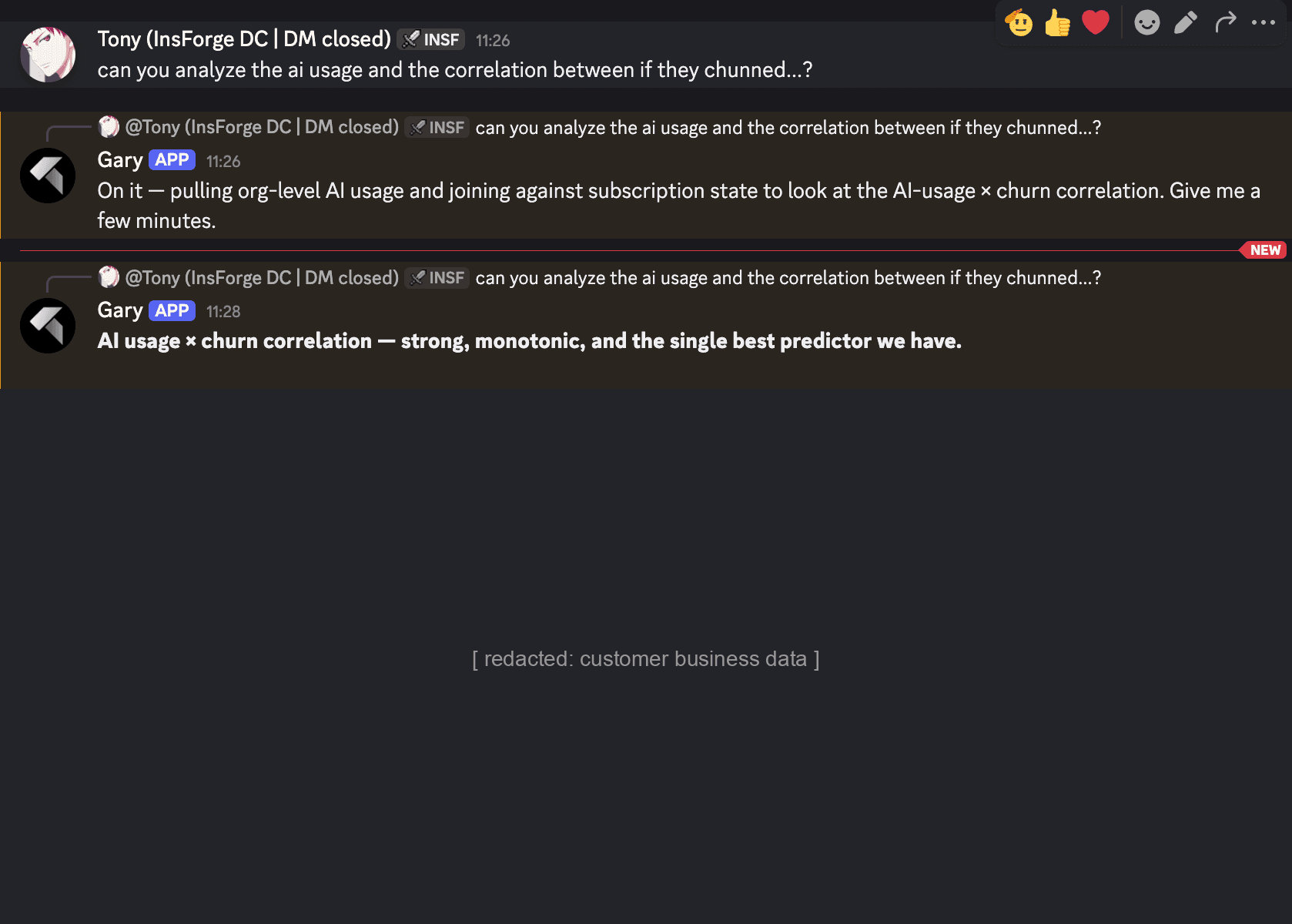
A real question, real data, answered in the same channel I asked it. No analyst pulled in. No notebook. No "let me get back to you tomorrow."
A different shape of task from the same week. I dropped a one liner asking for a Notion page on our AI architecture. The agent walked the codebase, asked where in the workspace the page should live, and posted a structured doc with TL;DR, deployment modes, code layout, and capabilities. The team had something to read, argue about, and edit by lunch:
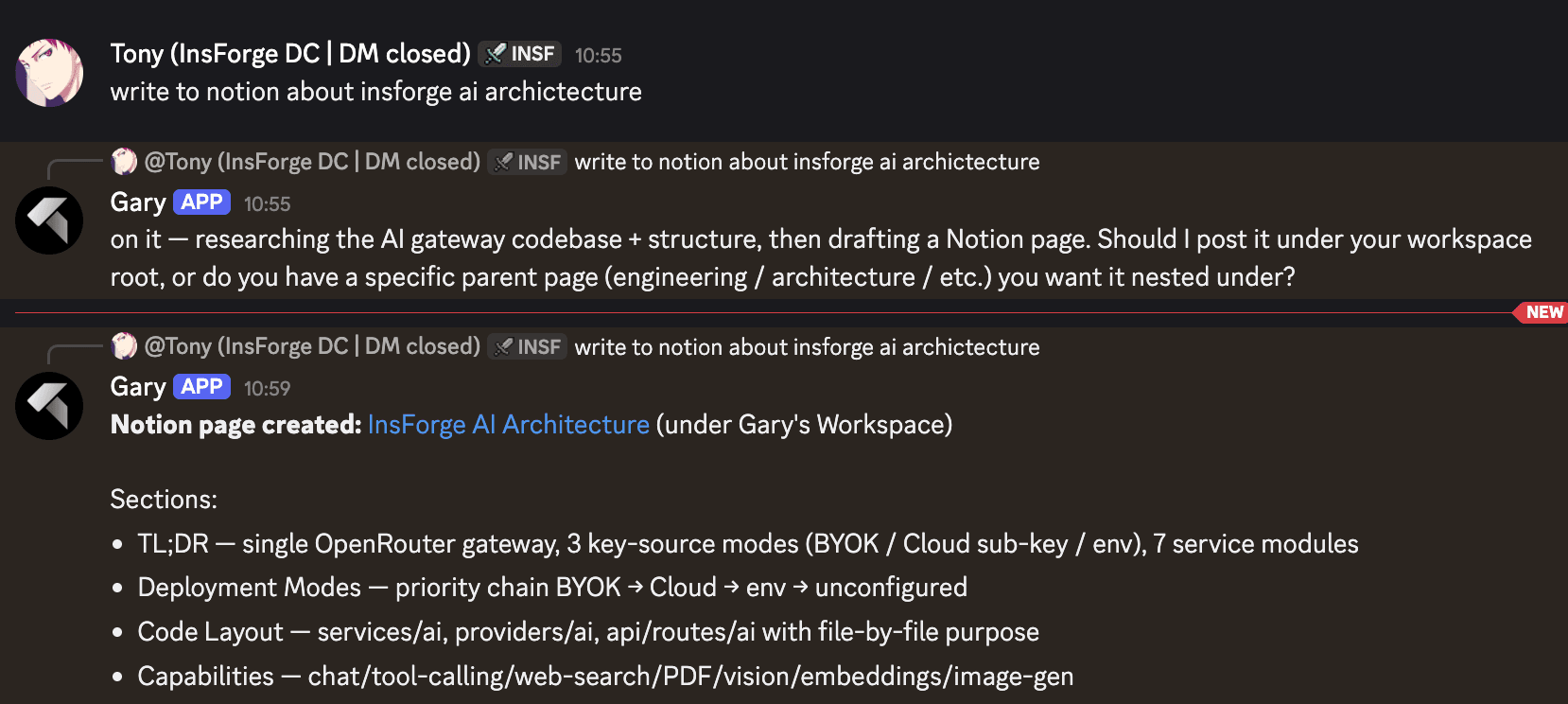
This is the pattern: agent does the legwork, posts the artifact, team discusses. Docs to argue about beats no docs to argue about.
First Line of Defense
The agent is not a generic Claude Code session. We bake in a set of Claude Code skills (runbooks for InstanceDown alerts, safe replica queries, project to host mapping, CloudWatch reading, GitHub issue filing) and seed persistent memory: the team, the services, the regions, what each environment is allowed to touch.
Its job is first responder. Read the question, pull the logs, form a hypothesis, post the evidence. Loop in a human only when the next step needs a write or a judgement call. Most things close out at the agent. The ones that escalate arrive with the investigation already done.
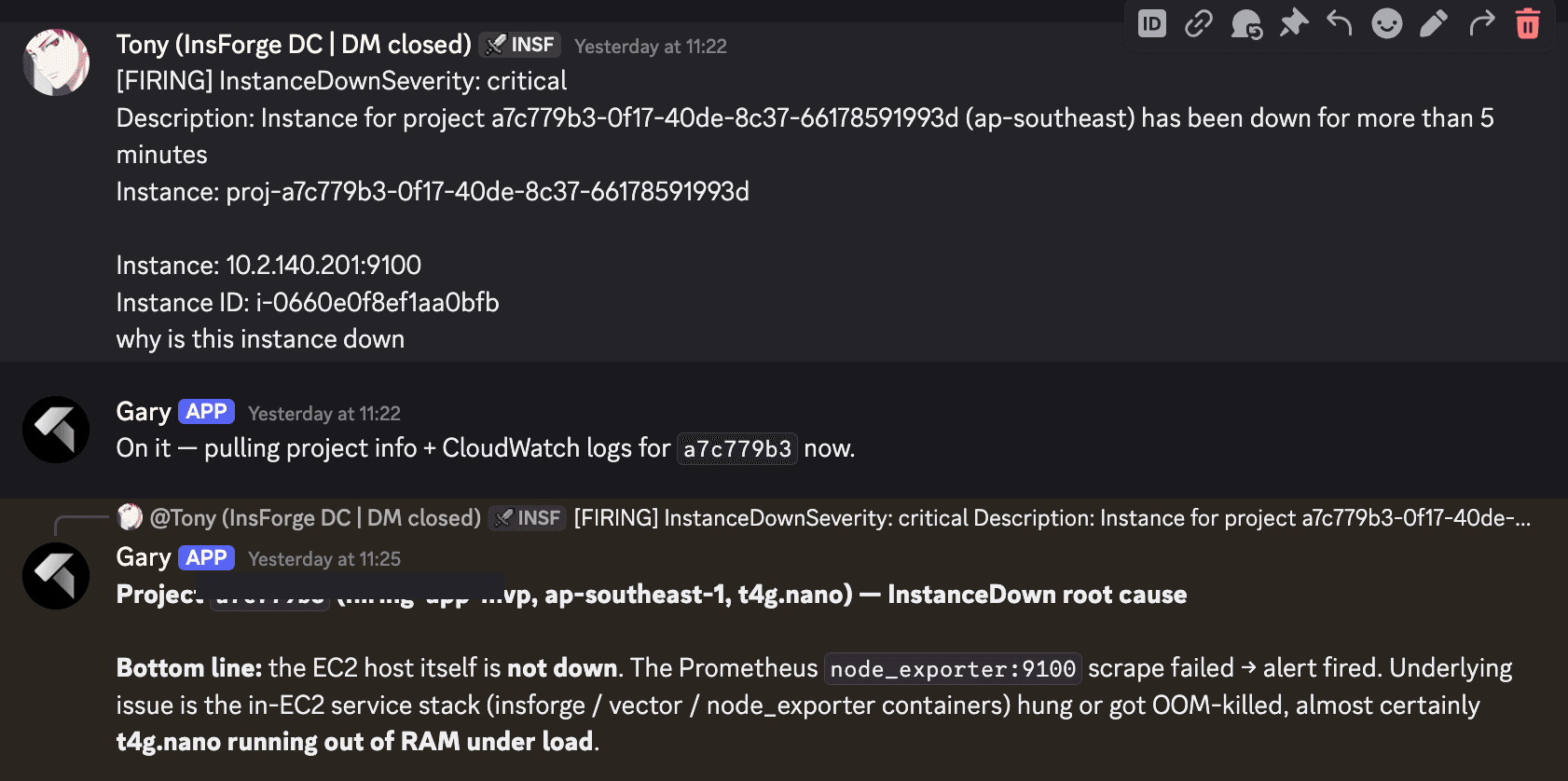
A textbook example. An InstanceDownSeverity: critical alert fired in ap-southeast-1. I asked one sentence. The agent pulled CloudWatch logs and the project metadata, confirmed the EC2 host itself was healthy with passing status checks and 3 to 5 percent CPU, and traced the page to the Prometheus node_exporter:9100 scrape failing on a t4g.nano that had OOM-killed the in-EC2 service stack under load. Not an EC2 problem. A node sizing problem.
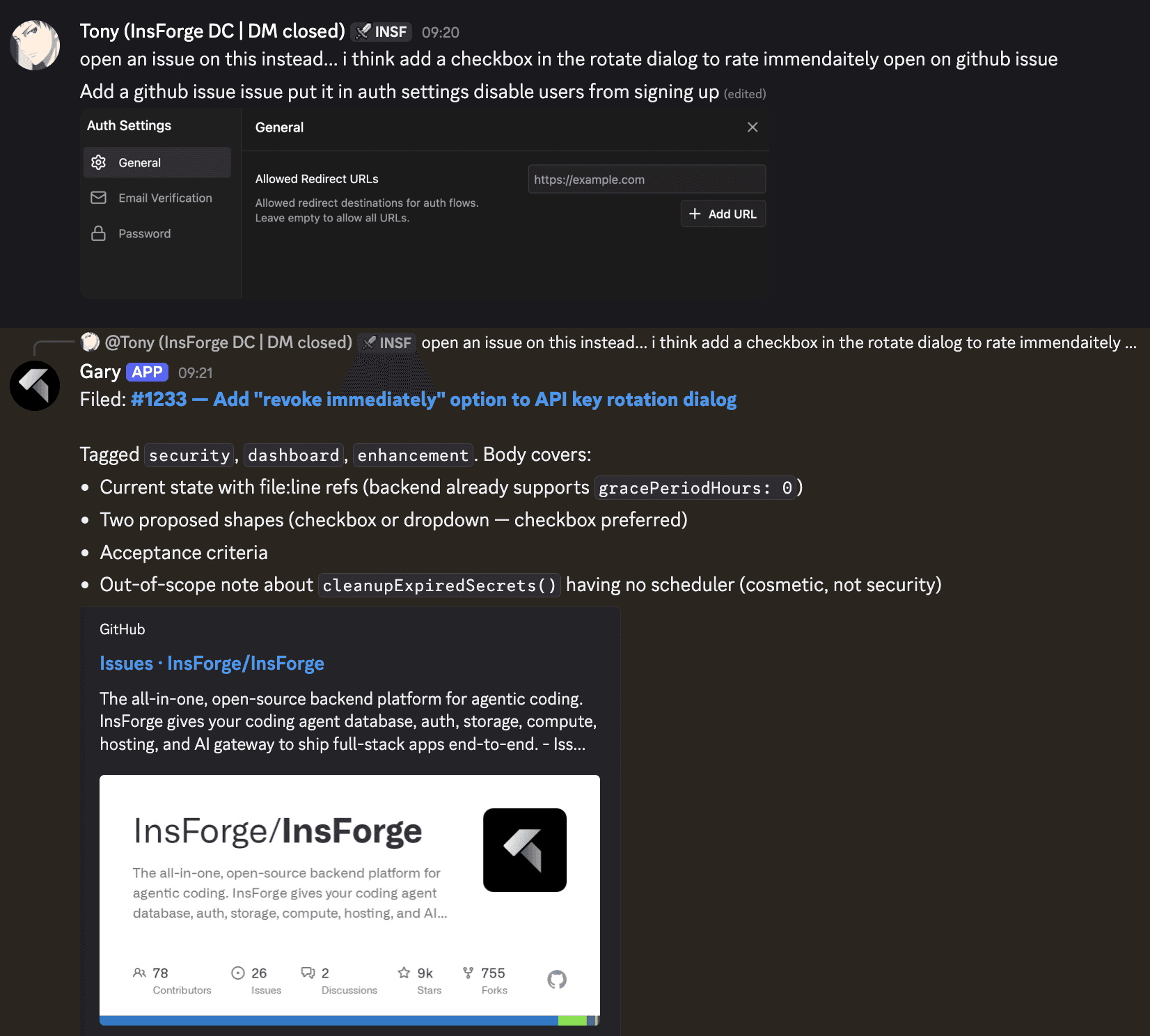
Another moment from the same week. I tossed off a feature idea about an API key rotation dialog. The agent read the relevant code, found the backend flag that already existed, drafted two implementation shapes, picked the one it preferred, wrote acceptance criteria, and filed a tagged GitHub issue. Before I had finished the message I started typing:
What This Got Us
Cheaper. The dominant cost of a local agent is not the subscription. It is the laptop that has to stay awake to host it. A VPS for a few dollars a day runs while everyone sleeps.
Safer. Credentials live behind a tightly scoped IAM role on one EC2 box, not on a laptop next to a browser running every site on the internet. Rotating a token is one AMI rebuild. A stolen laptop does not give an attacker the agent's powers.
Easier to control. Anyone in the channel can hand the agent a task. The CTO can scroll back and read the whole transcript. Adding a connector is one change to the AMI, not a deploy to eight laptops.
Portable. The Discord client is the agent client. Pull out your phone at dinner or on a walk, type the question, get the same answer you would at the desk. No laptop, no SSH, no VPN.
Talk To Us
If you are thinking about running the same setup, or just want to compare notes on how your team runs its agent workload, ping us in the InsForge Discord. We are happy to share what we built and walk through what worked and what did not.
If you are running Claude Code locally for a team larger than two, you are paying more than you need to and seeing less than you should. Move it to a VPS. Bake an image. Point a Discord or Slack channel at it.