
We have been using MCPMark to study how MCP servers affect agent performance on database tasks. In our earlier MCPMark benchmark post, we used it to compare MCP workflows across database tasks and understand how backend context affects agent reliability.
Agentic development, however, no longer runs through MCP alone.
Agents now work through CLIs, skills, docs, local files, migrations, MCP tools, and product-specific operating guides. We needed a benchmark that could answer a different question: which workflow actually helps an agent configure a backend correctly, repeatedly, and with reasonable cost?
That is the motivation behind the InsForge Agent Benchmark. It is experimental, open source, and still evolving. This first version focuses on database work because DB tasks expose the exact failure modes agents tend to struggle with: access control, data invariants, and vector retrieval logic.
The short version:
- InsForge CLI+Skills stood out on repeatability in this first run: 30/30 pass@3, 27/30 pass^3, and 86/90 passed attempts.
- Repeatability appears to be the most useful signal here, not just one successful run or the lowest token count.
- Skills seemed most helpful when they acted as narrow operating manuals, not broad documentation dumps.
Methodology
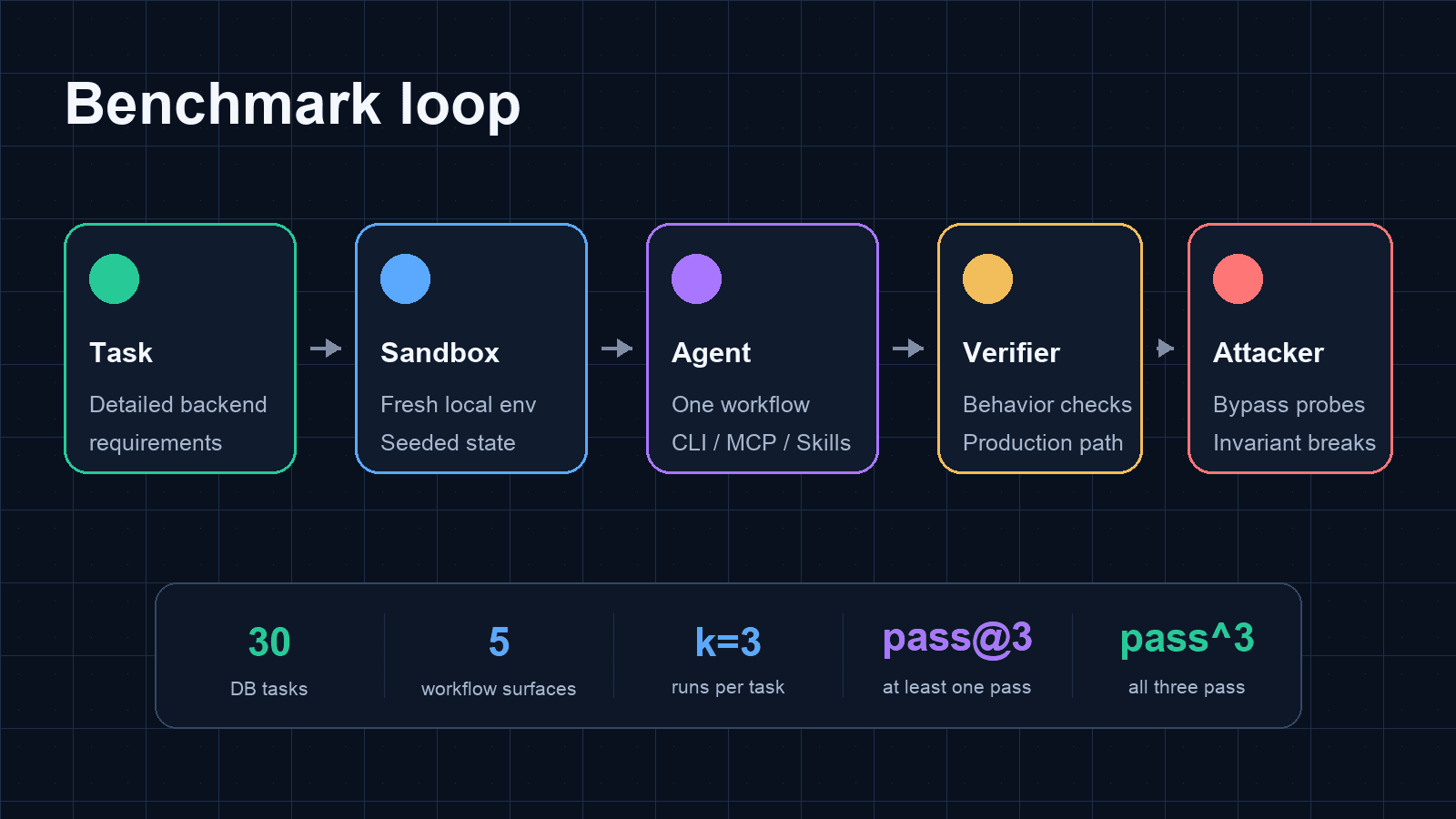
Each task gives the agent a specific backend implementation goal with detailed requirements. The agent configures the backend through one workflow surface, and independent verifier and attacker checks test whether the resulting backend behavior satisfies the task.
The benchmark loop is:
- Start a fresh local sandbox for the provider.
- Prepare deterministic task state and seed data.
- Give the agent a provider-neutral backend configuration task.
- Let the agent work through exactly one workflow surface.
- Run a verifier through the production-facing path.
- Run an attacker that probes bypasses, stale access, forged writes, bad rankings, or invariant breaks.
- Record pass/fail, time, token usage, cache-token rate, and logs.
We ran k=3: three independent attempts for every task and workflow.
The five workflows in this run were:
| Provider | Workflow |
|---|---|
| InsForge | CLI+Skills |
| InsForge | MCP |
| Supabase | CLI+Skills |
| Supabase | MCP |
| Supabase | MCP+Skills |
All tasks are centralized and provider-neutral. The task set READMEs are public:
Overall Results
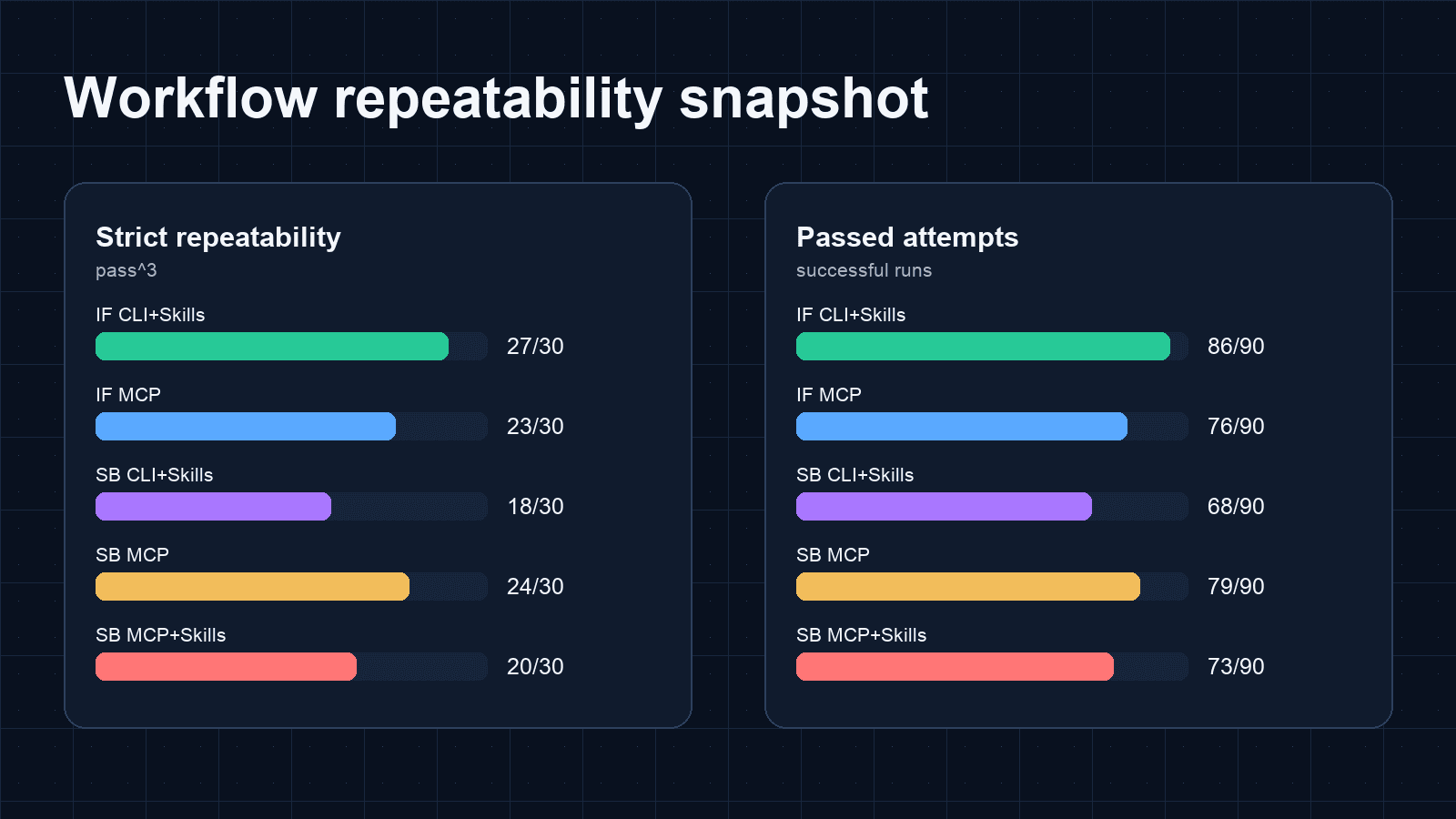
Across 30 tasks and 90 attempts per workflow, InsForge CLI+Skills stood out on repeatability in this preliminary run: 30/30 pass@3, 27/30 pass^3, and 86/90 passed attempts.
In the tables below, pass@3 means at least one of three independent attempts passed. pass^3 is stricter: all three attempts must pass. We also report non-cache tokens because they are closer to marginal cost than total context volume, while cache-token rate gives a sense of how much repeated context the workflow carries.
| Workflow | pass@3 | pass^3 | Passed attempts | Total time | Non-cache tokens | Cache-token rate |
|---|---|---|---|---|---|---|
| InsForge CLI+Skills | 30/30 | 27/30 | 86/90 | 3h 23m | 923K | 97.0% |
| InsForge MCP | 29/30 | 23/30 | 76/90 | 2h 39m | 724K | 95.9% |
| Supabase CLI+Skills | 27/30 | 18/30 | 68/90 | 3h 37m | 906K | 97.7% |
| Supabase MCP | 29/30 | 24/30 | 79/90 | 2h 34m | 774K | 94.0% |
| Supabase MCP+Skills | 27/30 | 20/30 | 73/90 | 3h 02m | 810K | 95.3% |
The most useful number here may not be raw token count. It may be repeatability. For backend work, a workflow needs to help the agent reach the same correct configuration again when it starts from a fresh sandbox.
In this run, InsForge CLI+Skills was the only workflow that reached pass@3 on every task across all three categories. It also had the highest strict stability score.
That points to a broader question for agent infrastructure: a useful workflow may not be just a way to expose tools. It may need to become a repeatable operating surface that helps the agent make the same backend decision correctly across fresh environments.
Access Control Tasks
The access-control set tests RLS and authorization patterns: ownership, team membership, embargoed content, JSONB profile visibility, ACL sharing, protected-field updates, hierarchical org access, role matrices, and recursion-safe membership helpers.
| Workflow | pass@3 | pass^3 | Passed attempts | Total time | Non-cache tokens | Cache-token rate |
|---|---|---|---|---|---|---|
| InsForge CLI+Skills | 10/10 | 8/10 | 28/30 | 1h 08m | 332K | 96.9% |
| InsForge MCP | 10/10 | 7/10 | 24/30 | 1h 04m | 271K | 95.4% |
| Supabase CLI+Skills | 8/10 | 5/10 | 20/30 | 1h 12m | 307K | 97.3% |
| Supabase MCP | 10/10 | 7/10 | 25/30 | 58m | 285K | 93.4% |
| Supabase MCP+Skills | 8/10 | 6/10 | 22/30 | 1h 08m | 279K | 94.4% |
Access control is where workflow guidance appears especially visible. The hard cases are not simply "create a policy." They are expiry, revocation, update masks, recursive membership, and role-dependent write paths.
InsForge CLI+Skills produced the highest passed-attempt count and the highest pass^3 result in this category. One possible interpretation is that workflow guidance becomes more valuable when the task has multiple security branches and a wrong answer can become a permission bug.
Integrity Tasks
The integrity set tests database invariants: exclusion constraints, server-maintained counters, soft-delete uniqueness, approval workflows, invite claiming, ledger balance triggers, moderation leases, archive freezes, guarded deletes, quotas, and append-only document history.
| Workflow | pass@3 | pass^3 | Passed attempts | Total time | Non-cache tokens | Cache-token rate |
|---|---|---|---|---|---|---|
| InsForge CLI+Skills | 11/11 | 10/11 | 31/33 | 1h 48m | 444K | 96.4% |
| InsForge MCP | 11/11 | 8/11 | 28/33 | 1h 19m | 355K | 95.3% |
| Supabase CLI+Skills | 10/11 | 4/11 | 21/33 | 1h 37m | 392K | 97.1% |
| Supabase MCP | 10/11 | 10/11 | 30/33 | 1h 13m | 358K | 92.4% |
| Supabase MCP+Skills | 10/11 | 6/11 | 25/33 | 1h 20m | 351K | 94.3% |
Integrity tasks are intentionally less about RLS and more about state that must remain true even when clients are malicious or concurrent.
This was the least one-dimensional category. Supabase MCP and InsForge CLI+Skills both reached 10/11 pass^3, while InsForge CLI+Skills reached every task at least once and had the highest passed-attempt count at 31/33.
That split is useful. Strict repeated success and per-attempt success are not always the same signal. For InsForge, the intermittent misses were concentrated in one hard workflow task that pushed the timeout boundary. That suggests a concrete product target: make complex migration planning faster without weakening the invariant checks.
Vector Tasks
The vector set tests DB-native vector retrieval without calling external embedding or LLM APIs. It covers metadata filters, thresholds, recommendations, parent document collapse, hybrid rank fusion, multi-vector weighting, ANN indexing, embedding-version selection, and diversity reranking.
| Workflow | pass@3 | pass^3 | Passed attempts | Total time | Non-cache tokens | Cache-token rate |
|---|---|---|---|---|---|---|
| InsForge CLI+Skills | 9/9 | 9/9 | 27/27 | 27m | 147K | 98.0% |
| InsForge MCP | 8/9 | 8/9 | 24/27 | 16m | 98K | 97.8% |
| Supabase CLI+Skills | 9/9 | 9/9 | 27/27 | 48m | 207K | 98.5% |
| Supabase MCP | 9/9 | 7/9 | 24/27 | 23m | 131K | 96.6% |
| Supabase MCP+Skills | 9/9 | 8/9 | 26/27 | 34m | 180K | 97.0% |
Vector looked comparatively clean for InsForge CLI+Skills in this run. It passed every attempt while staying close to one minute per task.
The harder pieces were score direction, rank fusion, parent collapse, stale embedding filters, and index-backed retrieval. Those are the cases that tend to make vector search fragile in real products.
What Skills Changed
One early lesson is that skills do not appear to automatically make agents better.
In this run, skills seemed most helpful when they acted like compact operating manuals for a specific workflow surface. The useful version of a skill may need to be narrow, opinionated, and close to the operations the agent is actually performing.
The InsForge CLI+Skills workflow gave the agent the backend-specific habits we want in production:
- Migration-first DDL: SQL is written as versioned backend changes instead of one-off commands.
- Supported schema boundaries: benchmark database work stays in
public. - Access-control recipes: recursive RLS traps, ownership fields, and security-sensitive helper functions are treated explicitly.
- Integrity patterns: constraints and triggers carry invariants that clients should not be able to bypass.
- Vector SQL contracts: score direction, filtering, and ranking semantics are defined in the database API.
The Supabase MCP+Skills run had lower strict stability than Supabase MCP in this matrix: 20/30 pass^3 versus 24/30 pass^3, with higher total time and non-cache token usage. That result points back to skill design rather than to skills as a category. Skills seem to need precision, scope, and alignment with the workflow surface the agent is actually using.
Why CLI Workflows Use More Tokens
CLI workflows tend to carry more context than MCP workflows largely because they work through local files, especially migrations.
The agent writes SQL into local migration files, edits them, applies them through the CLI, and sometimes reads the files again while reasoning about the next step. Those files become part of the agent context across turns.
That local-file loop is useful because migrations are auditable and production-friendly, but it also adds context. In this first run, the two CLI workflows used 923K and 906K non-cache tokens across 90 attempts, with cache-token rates around 97%. That suggests the repeated migration context was mostly cacheable, but still worth optimizing.
The product question is how to keep the migration-first workflow while making the agent's local-file loop lighter. Better migration summaries, smaller skill entry points, and sharper CLI output may reduce repeated context without changing the workflow itself.
What Comes Next
This benchmark is also a way to improve agent-operated infrastructure, not just a report card.
We will expand it in two directions.
First, horizontal provider comparison. InsForge and Supabase are the first pair because they expose similar backend primitives. We want to add more providers and broaden the workflow matrix.
Second, vertical module coverage. Database work is only one slice of backend development. The next categories should cover auth, storage, site deployment, payments, email, realtime, AI gateway, and compute. That lets us compare InsForge site deployment against Vercel-style workflows, payments against Stripe and Stripe CLI workflows, and other modules where agents need to configure infrastructure, not just write app code.
The goal is bigger than one benchmark post. We want to develop a public benchmark for the Skills era, and use it to keep sharpening InsForge itself: faster tools, safer defaults, clearer skills, and more reliable agent workflows.
Read the source, run the tasks, and open an issue if you find a weak spot: