
LLMs have been steadily improving on SDE benchmarks. But in real work, the net productivity hasn’t improved at the same pace.
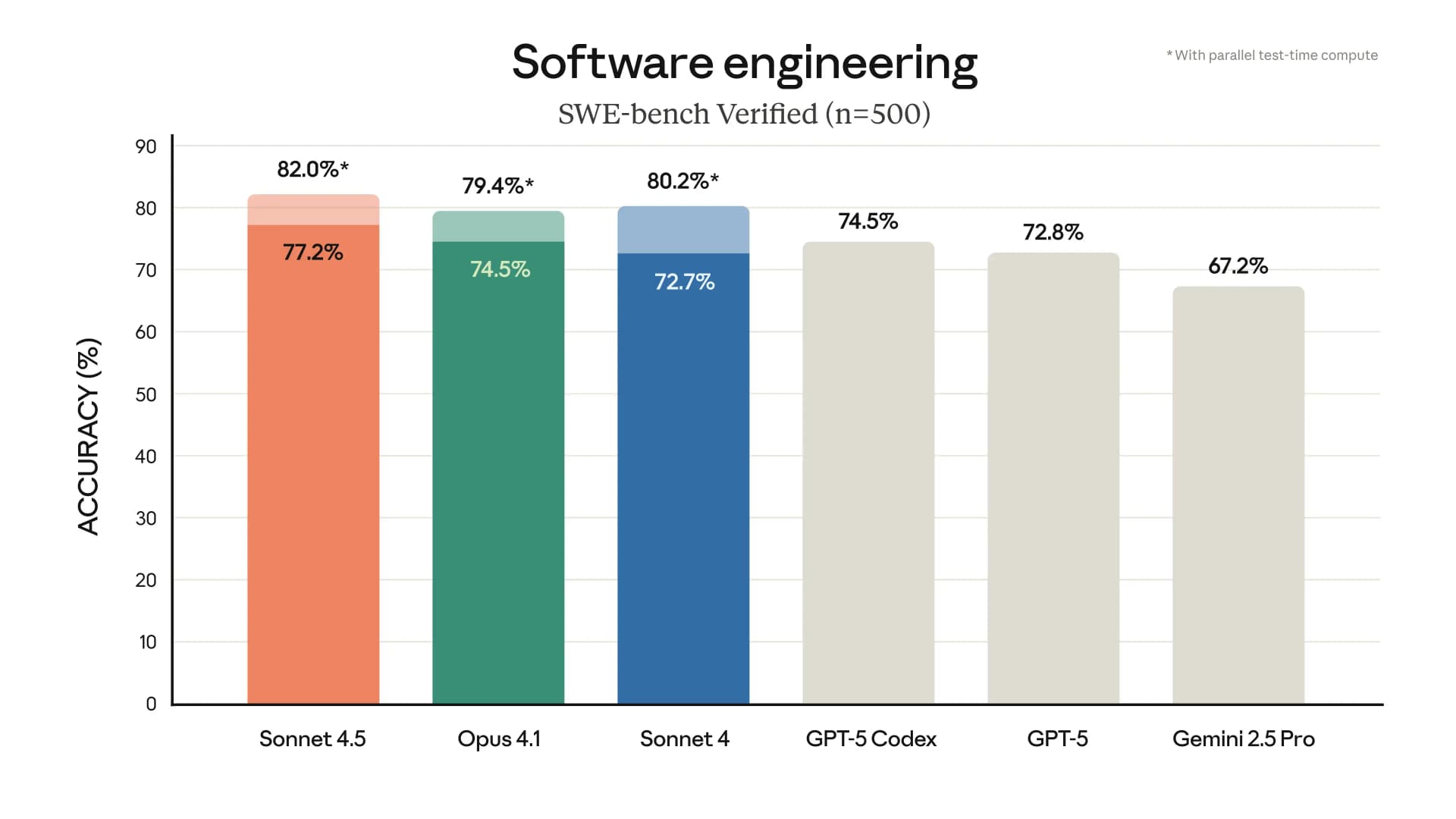
There’s still a lot of back-and-forth editing: small edits, retried, and manual fixes. In the end, a human still has to step in and clean things up. This isn’t a limitation of the model’s intelligence, it’s a context problem. Without solid context engineering, even the best model will make wrong assumptions and produce messy code.
Context engineering means giving the model the right information inside its context window: the information that is accurate, relevant, and scoped to the right level of detail for the next step.
In this post, we’ll look at why context matters so much in software development, and the best practices to make coding agents work better.
The Real Problem: Limited Context
LLMs generate based on the data they were trained on and the context you provide at runtime. That means their understanding is always partial and sometimes inaccurate.
This limitation has 2 main forms:
- Outdated Context: knowledge from pretraining lags behind new frameworks, libraries, and tools
- Incomplete Context: the model can’t access information beyond the codebase, missing critical details like APIs, schemas, runtime state, and external services.
Outdated Context
LLMs’ training and release take month, so by nature when they came out, the knowledge they have already outdated, often months behind.
| Model Name | Cut-off Date | Months Behind |
|---|---|---|
| Claude Sonnet 4.5 | 2025.01 | 9 |
| GPT-5 | 2024.09 | 13 |
| Gemini 2.5 Pro | 2025.01 | 9 |
That’s why even the latest models often use deprecated libraries, old API patterns, or outdated syntax that no one ships in production anymore. In fast-moving frameworks like React, Next.js, or Tailwind, a few months of drift can already mean broken builds or visual bugs.
In January 2025, Tailwind released CSS v4.0, a breaking change with no backward compatibility. The PostCSS plugin was moved from the tailwindcss package to @tailwindcss/postcss, and many syntax and config rules were rewritten. These updates caused widespread build failures and confused AI tools, which defaulted to the older v3.4 syntax. Although Tailwind provided a migration command npx @tailwindcss/upgrade to automatically fix syntax errors and update configurations, AI tools often fail to see the full picture as they only read the error messages and end up producing partially functional outdated changes. After multiple failed attempts to adapt, AI tools will ultimately recommended sticking with the previous version.
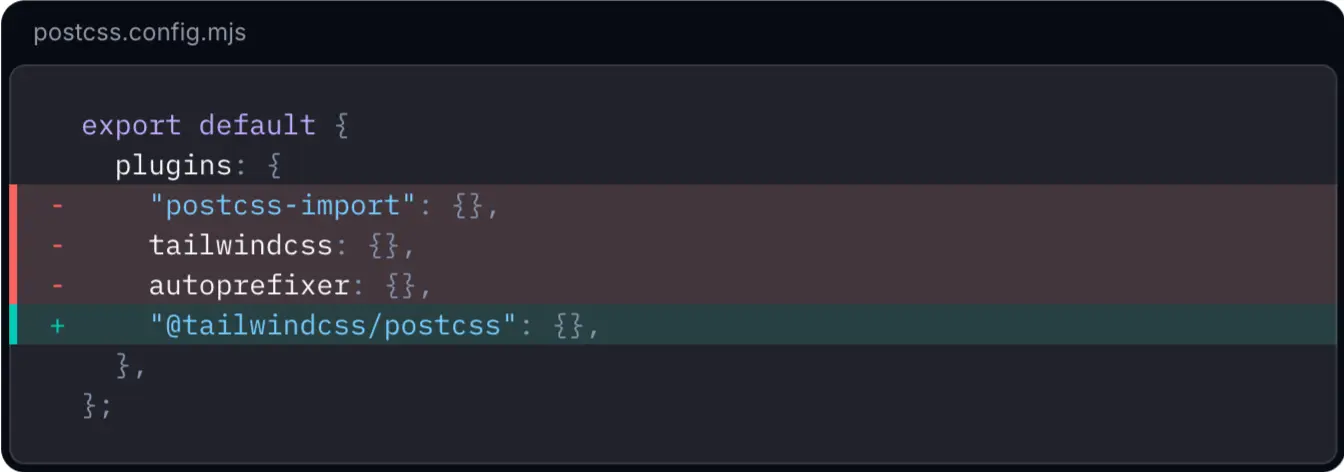
Source: Tailwind CSS v4.0
Backend frameworks and databases evolve too. When PostgreSQL or Prisma changes query behavior or migration syntax, a model still trained on older versions may generate code that runs without errors but returns wrong data. It passes tests, but silently fails in production.
In PostgreSQL 18 release in September 2025, the database changed how it compares text. Old version treated certain characters as the same. For examples ß(the German alphabet) and ss were considered equal. The new version now follows stricter international (Unicode) rules, where ß and ss are not considered equal.
Previously, a query like:
SELECT * FROM users WHERE name ILIKE 'straße';
would match both “straße” and “strasse.”
After the update, it only finds “straße.”
To fix it, specify the correct collation:
SELECT * FROM users
WHERE name ILIKE 'straße' COLLATE "de_DE";
Adding COLLATE "de_DE" restores German language comparison so both versions match.
Or, normalize all text to English (for example, convert ß → ss) before saving or searching.
However, AI models were trained on older PostgreSQL versions and thus won’t detect this change. They will still generate the first query, assume it works, and silently miss data in production, breaking multilingual search accuracy and user trust without showing any error.
Source: PostgreSQL 18 Released!
Incomplete Context
Coding agents are good at retrieving and searching the codebase to better understand the project, however, the codebase only tells part of the story. Real-world software depends on many invisible layers of context that models can’t observe by default:
- How authentication, authorization, and user identity affect each flow
- Internal / external APIs and microservices that are not part of the local repo
- Database schemas, migrations, and production data
- Serverless or backend function contracts that define inputs and outputs
- Environment configuration and secrets
- Logs that reveal what actually happened during execution
When the agent cannot access these facts, it guesses. That is when errors appear that look confident but are completely wrong:
- It queries fields that were removed months ago
- It calls endpoints that do not exist
- It produces code that bypasses real authorization rules
Suddenly, the workflow becomes a cycle of generate → inspect → correct → retry. The net productivity gains might be negative.
The limitation is not intelligence. It is context. If we want agents to build production quality software, they need the right information available at every step inside the loop. That context must stay accurate, fresh, and tightly scoped to the change they are making right now.
Prompt Engineering vs. Context Engineering
Prompt engineering can solve this issue to some extent by giving the detailed instruction in current context window one-time. However, agents run in loops, every generation and actions are changing the status, so the context they are getting from the initial input prompt are no longer accurate. That’s why a solid context engineering methodology is needed to ensure agent’s context window has relevant source of truth context every generation.
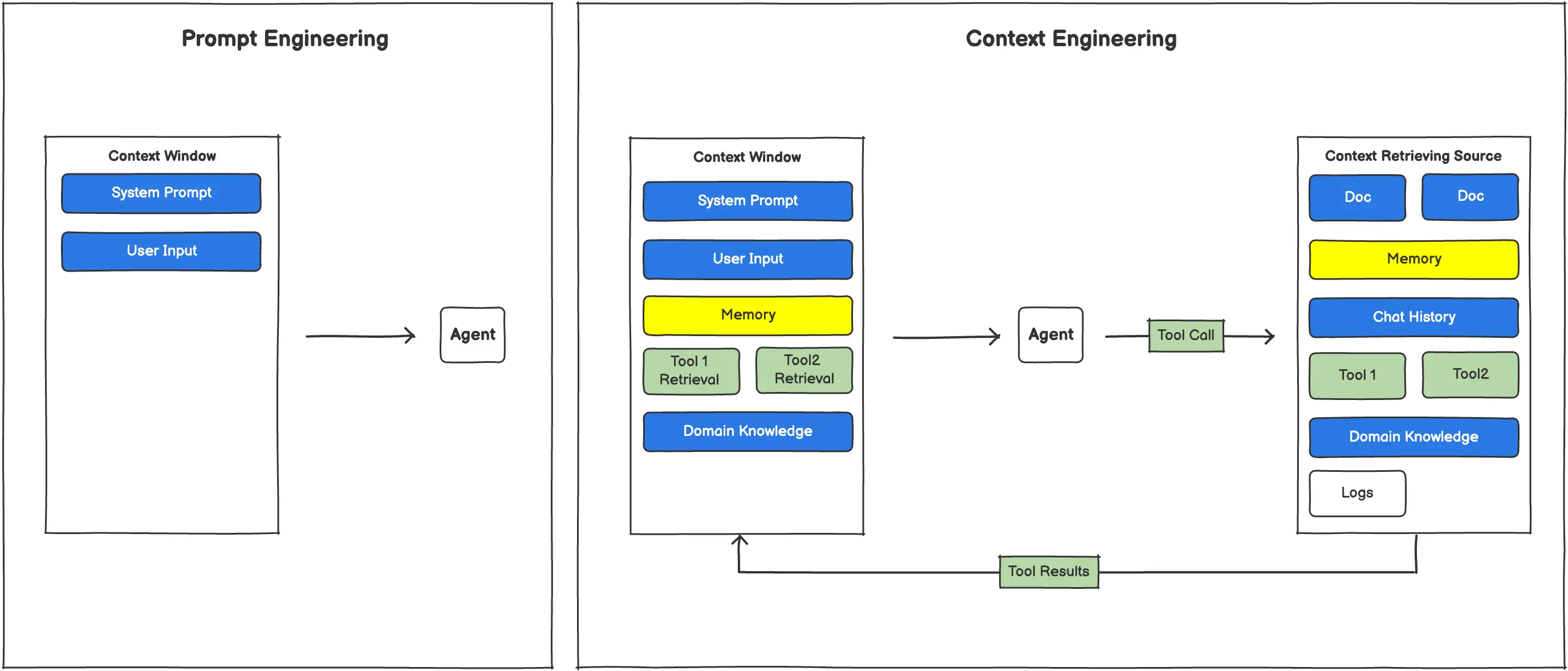
Why Context Engineering is Hard
It sounds simple: give the agent the information it needs and let it code. In real usage, it is much harder than it looks.
Limited context window means constant tradeoffs
Even with models that advertise 200K token context windows, the usable space is often closer to half of that. Agents already load:
- System prompts and guardrails
- Tool metadata and action history
- Memory or state summaries
Cursor, for example, can start with 20K to 40K tokens occupied before the user adds anything. Here is a fresh session showing 13 percent of context already consumed:
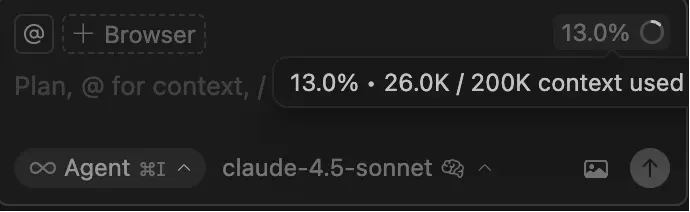
Once the model crosses its comfort threshold and starts compacting, output quality begins to drop. So retrieval is always a balancing act.
There are two common failure modes:
- Too specific: The agent fetches every detail it can find. The window fills. Earlier context gets pushed out.
- Example: retrieving full database metadata including internal schemas like
authandstoragecan add 20K to 30K tokens of irrelevant information, causing the model to “forget” essential logic it wrote minutes ago.
- Example: retrieving full database metadata including internal schemas like
- Too vague: High level context saves tokens but removes constraints the agent must follow. The missing details turn into hallucinations later.
- Example: retrieving the
money_balancetable structure, but not its RLS (Row Level Security) policies. The model then writes an update that bypasses authorization. In production, a malicious user could set their own balance to infinity.
- Example: retrieving the
The right context changes every step
Software development is dynamic. After every generation:
- Files change
- APIs evolve
- Schemas update
- Logic iterates
What was relevant 30 seconds ago may be updated now. The agent can’t rely on the initial prompt or a static snapshot. It must continuously re-evaluate what matters as the code changes. Without this, the agent drifts and starts breaking its own work.
External dependencies create blind spots
Modern applications rely on many systems outside the repo:
- Identity & payments
- Storage and media pipelines
- Internal services owned by other teams
- Third party APIs that change silently
If the agent can’t query or retrieve these contracts automatically, it guesses, writing integration code that compiles, but returns the wrong data or fails in production. Those blind spots become outages.
The Principles of Good Context Engineering
To help agents build reliable software, we cannot rely on the model’s intelligence alone. We must provide the right context at the right time so each generation stays aligned with the system.
There are 2 core principles.
Principle 1: Hierarchical context
The goal is not to load everything. The goal is to load only what is needed now, and guide the agent to fetch the next piece when it becomes relevant.
Two layers work together:
- Global context: schemas, routing, module relationships, high-level instruction
- Local context: scoped information that enables the current change
Example: creating the money_balance table
- First run: provide database structure
- The agent sees there is a
userstable
- The agent sees there is a
- Next run: provide detailed
usersmetadata- So it identifies
users.idas the correct foreign key
- So it identifies
- Then: implement Row Level Security rules correctly
Principle 2: Source of truth
Context must always reflect the real backend. A snapshot becomes stale the moment the agent modifies the system.
Without a single source of truth:
- The agent retrieves an outdated schema
- It generates code that reintroduces removed fields
- On later iterations, it accidentally undoes its own changes
This is a common failure in current coding agents: the agent breaks code it previously fixed, because its context has not updated.
A strong context foundation requires:
- One authoritative location for backend truth
- Automatic updates triggered by code or schema changes
- Version tracking to support debugging and rollback
The system protects the workflow from drift so every generation builds forward instead of sideways.
What Good Context Looks Like in Practice
Context engineering is a iterative process. Each step succeeds because the system ensures the agent has exactly the relevant information for the current run, plus a clear retrieval path for the next one.
InsForge’s MCP tools are built around this workflow, and it implements both principles directly into MCP tool design.
Global context
get-backend-metadata returns a high level backend structure, and suggests the next step: "To retrieve detailed schema information for a specific table, call the get-table-schema tool with the table name."
{
"auth": {
"oauths": [
{
"provider": "google",
"clientId": null,
"redirectUri": null,
"scopes": ["openid", "email", "profile"],
"useSharedKey": true
}
]
},
"database": {
"tables": [
{
"tableName": "users",
"recordCount": 1
}
],
"hint": "To retrieve detailed schema information for a specific table, call the get-table-schema tool with the table name."
},
"storage": {
"buckets": [],
"totalSizeInGB": 0
},
"aiIntegration": {
"models": [
{
"inputModality": ["text", "image"],
"outputModality": ["text"],
"modelId": "anthropic/claude-sonnet-4.5"
}
]
},
"version": "1.0.0"
}
Local context
get-table-schema returns detailed table definition including triggers, functions and RLS policies
{
"users": {
"schema": [
{
"columnName": "id",
"dataType": "uuid",
"characterMaximumLength": null,
"isNullable": "NO",
"columnDefault": null
},
{
"columnName": "nickname",
"dataType": "text",
"characterMaximumLength": null,
"isNullable": "YES",
"columnDefault": null
},
{
"columnName": "bio",
"dataType": "text",
"characterMaximumLength": null,
"isNullable": "YES",
"columnDefault": null
},
{
"columnName": "created_at",
"dataType": "timestamp with time zone",
"characterMaximumLength": null,
"isNullable": "YES",
"columnDefault": "now()"
},
{
"columnName": "updated_at",
"dataType": "timestamp with time zone",
"characterMaximumLength": null,
"isNullable": "YES",
"columnDefault": "now()"
}
],
"indexes": [
{
"indexname": "users_pkey",
"indexdef": "CREATE UNIQUE INDEX users_pkey ON public.users USING btree (id)",
"isUnique": true,
"isPrimary": true
}
],
"foreignKeys": [
{
"constraintName": "users_id_fkey",
"columnName": "id",
"foreignTableName": "accounts",
"foreignColumnName": "id",
"deleteRule": "CASCADE",
"updateRule": "NO ACTION"
}
],
"rlsEnabled": true,
"policies": [
{
"policyname": "Enable read access for all users",
"cmd": "SELECT",
"roles": "{public}",
"qual": "true",
"withCheck": null
},
{
"policyname": "Disable delete for users",
"cmd": "DELETE",
"roles": "{authenticated}",
"qual": "false",
"withCheck": null
},
{
"policyname": "Enable update for users based on user_id",
"cmd": "UPDATE",
"roles": "{authenticated}",
"qual": "(uid() = id)",
"withCheck": "(uid() = id)"
},
{
"policyname": "Allow project_admin to update any user",
"cmd": "UPDATE",
"roles": "{project_admin}",
"qual": "true",
"withCheck": "true"
}
],
"triggers": [],
"rows": []
}
}
Together, these form a context loop where:
- The agent always retrieves current knowledge
- It never overloads the window
- It follows the right dependency chain
- Every generation starts from the truth, not a memory
What’s Next
Good models write code. Great models write the right code with the right context.
The future of software development will not be defined by larger models alone. It will be defined by how well we keep context accurate, current, and aligned through every step of the development loop.
This is how AI will finally ship production software. Fewer regressions. Less cleanup. More real progress.
We are building the backend for AI assisted development. If this future excites you, join us early:
Let’s build a world where developers focus on ideas, and agents take care of the rest. Here’s our roadmap.