TL;DR
- The problem: AI agents handle frontend tasks well, but backend operations expose a consistent gap. Even when MCP is connected, most backends return table names without record counts, schema without RLS state, and tool responses without success signals. The agent fills that gap with extra queries, retries, and guesses.
- Why existing backends fall short: Platforms like Supabase and Postgres MCP were designed for human operators who can read a dashboard, check a UI, and make judgment calls. When an agent is the one operating the backend, that design assumption breaks at every step.
- What changes with an agent-native backend: InsForge builds MCP into the backend from the start, not on top of it. Two tool calls give the agent a full map of the backend and deep context for the table it is working on, with live record counts, RLS state, and policy definitions returned before the agent writes a single query. Across 21 MCPMark tasks, the design produces 47.6% Pass⁴ accuracy, 30% fewer tokens, and 1.6x faster execution compared to Postgres MCP and Supabase MCP.
Introduction
AI agents handle frontend tasks well. Give one a component structure, a routing pattern, or a state management problem, and it will usually get it right. But backend operations are different.
Ask an agent to implement Row Level Security on a production Postgres database. It will write the policies, run the migration, and return success. But if the MCP server it is connected to does not expose RLS status in its schema response, the agent has no way to verify what it actually changed. It assumes the operation worked. The policies it wrote may be incomplete, applied to the wrong roles, or missing entire tables. Nothing throws an error, but the data access rules are silently wrong.
This is not a model quality problem. It is a context problem. And it happens consistently, across models, across tasks, even when MCP is part of the setup.
In this article, we examine where agents consistently fail on backend tasks, what the current MCP layer design in most backends is missing, and how a backend built specifically for agents changes the execution pattern.
MCP Exists but Agents Still Fail
Most major backend platforms have MCP servers now. Supabase has one. Postgres has one. The assumption is that once you connect an agent to a backend via MCP, the backend visibility problem is solved, but connecting to an MCP does not determine what it returns.
MCP is a protocol. It defines how tools are called and how responses are structured. It does not define what those responses contain. That part is entirely up to whoever built the MCP server.
Here is what Supabase MCP returns when an agent calls list_tables:
["users", "orders", "products", "sessions"]
The response contains table names only, with no record counts, no foreign key relationships, no RLS status, no policy definitions, no trigger logic, and no index information.
Supabase was built for a specific use case, and it does that well. Tools like Lovable, Bolt, and v0 use it because it is fast to set up, visually manageable, and good for getting a product off the ground quickly. The dashboard-first design works for that workflow because a human is always in the loop, reading errors, checking the UI, and making judgment calls.
When an agent is the one operating the backend, there is no human in the loop. The agent cannot open the Supabase dashboard and read the RLS policy panel. It can only work with what the MCP tool returns. And what it returns is not enough to act correctly on anything beyond a basic read or write.
So the agent does what any system does when it lacks information. It runs more queries. It guesses. It retries. Each of those extra steps costs tokens and time, and none of them are guaranteed to surface the right answer.
Every extra query the agent runs, every retry, every guess is a symptom of the same underlying gap. The MCP layer was built for a human operator, and the agent is paying the cost of that assumption at runtime.
How Agents Actually Fail
The surface problem shows up in four consistent failure patterns. These are not edge cases or misconfigured setups. They happen across models, across tasks, and across backends that have MCP connected.
Two of the failures below reference MCPMark tasks. MCPMark is an open-source benchmark that measures how well MCP servers support language models on real database tasks. Each task is a non-trivial backend operation run against actual databases with real data volumes. The task names map directly to the operation being tested. They are used here because they are reproducible, measurable, and not hypothetical.
Failure 1: Non-Deterministic Tool Calls
Agents interact with backends by calling tools, and some of those tools trigger real, irreversible operations like creating a resource, provisioning infrastructure, or writing to a database. When one of those calls times out, the agent has no success signal to work from. The tool response came back empty, the operation has no ID, and the backend has no idempotency key, so the agent does what it was built to do: it retries. By the time the second request lands, the first one has already gone through. Two identical resources now exist in production, and neither the agent nor the developer caught it in real time.
APIs built for humans assume someone will check the dashboard after an operation. Agents cannot do that. They need a deterministic success or failure signal from the tool response itself, or they will keep retrying until something breaks.
Failure 2: Schema Blindness in Real Databases
The MCPMark task employees__employee_demographics_report asks an agent to generate gender statistics, age group breakdowns, birth month distributions, and hiring year summaries from an HR database.
The employee table had 300,024 rows. The salary table had 2,844,047 rows. That is roughly 9.5 salary records per employee.
The MCP server returns table names and column definitions. No record counts. The agent sees a join between two tables and writes the most natural query:
SELECT gender, COUNT(*) -- counts salary rows, not employees
FROM employee e
LEFT JOIN salary s ON e.id = s.employee_id;
The query runs clean. No error. The output is 9.5 times too large because COUNT(*) multiplies across joined salary rows instead of counting distinct employees. The agent returns it as correct.
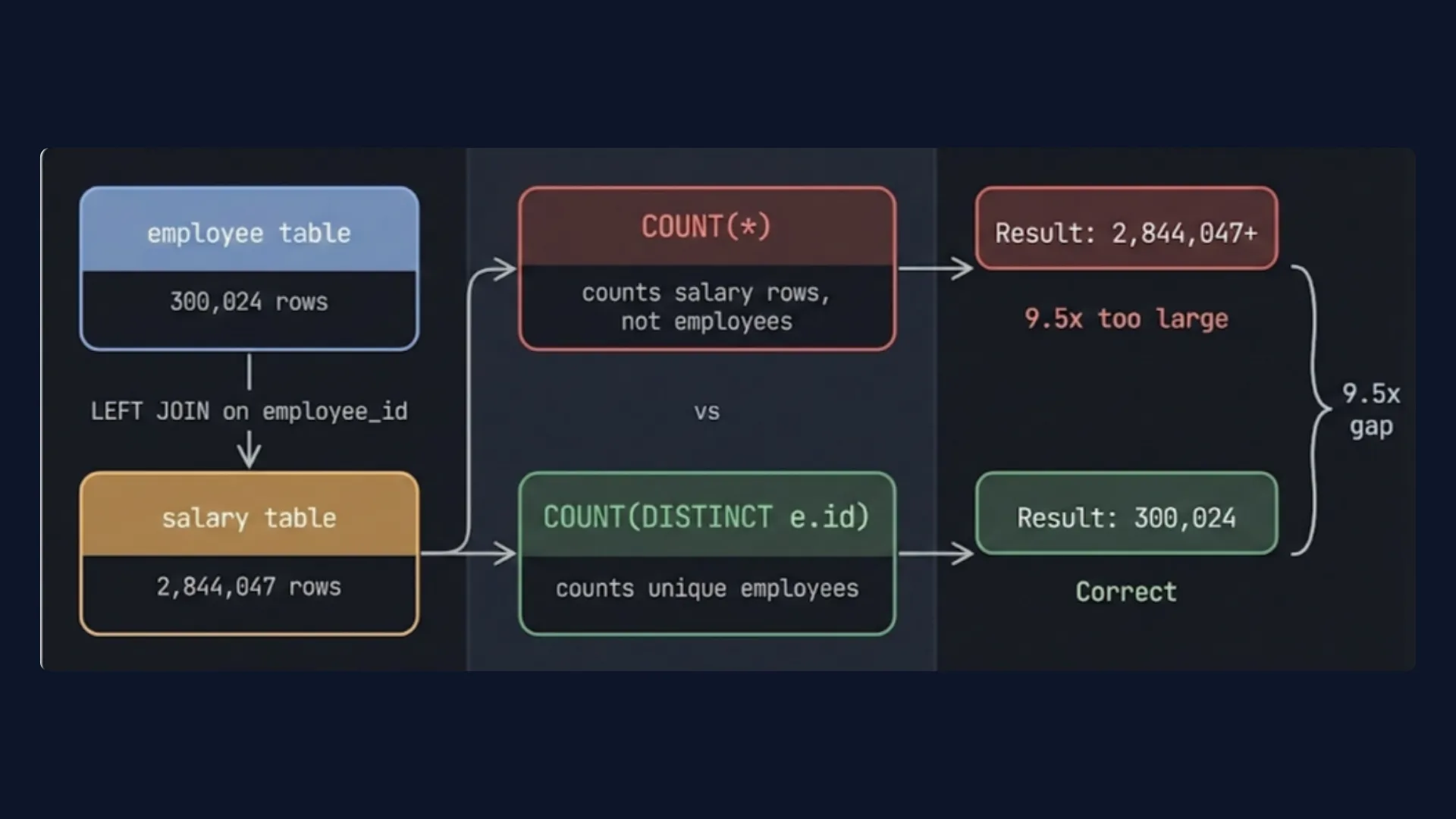
The backend had the record counts. It just never surfaced them.
Failure 3: Missing Context Compounds Cost
The MCPMark task security__rls_business_access asks an agent to implement Row Level Security policies across 5 tables on a social media platform.
The MCP server's get_object_details returns schema, columns, constraints, and indexes for each table. No rlsEnabled field. No policies array. The agent does not know RLS is disabled. It has to run a separate SQL query just to check the current RLS status before it can start the actual task. Then it runs verification queries after implementation to confirm the policies applied correctly.
list_schemas → schema names only
list_objects → table names only
get_object_details × 5 → schema, no RLS status
execute_sql → check current RLS status
execute_sql × 8 → create functions, enable RLS, create policies
execute_sql × 4 → verification queries
23 turns. 581K tokens. Every extra query in that path exists because one field was missing from the original response.
Failure 4: No Guardrails for Autonomous Operations
An agent runs a schema migration. The migration has a logic error. There is no audit log of what the agent changed, no agent-scoped permissions limiting what operations it can run, and no rollback path. Production breaks. Nothing was recorded.
Backends built for human developers assume a human is reviewing the migration before it runs. When an agent is the one initiating the change, that assumption breaks. There is no mechanism to scope what the agent is allowed to modify, no record of what it actually did, and no way to recover cleanly if something goes wrong.
What an Agent-Native Backend Looks Like
The failures in the previous section share a common cause. The backend gave the agent a name when it needed a state. A table name when it needed a record count. A schema when it needed a policy definition.
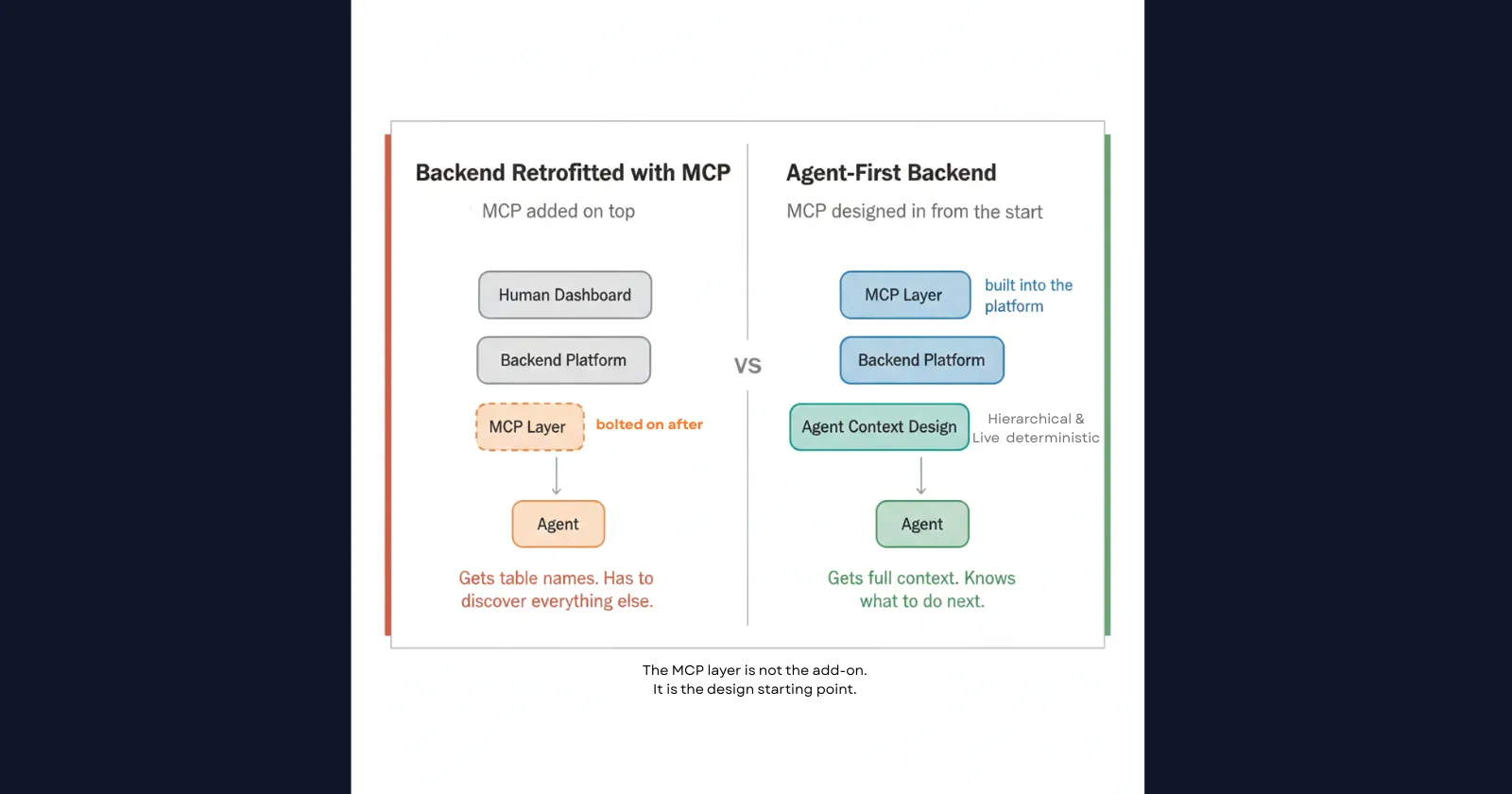
Fixing this is not about a better prompt or a smarter model. It is about what the MCP layer returns by default. That means the backend itself has to be designed around what an agent needs to see, not retrofitted with MCP after the fact.
That is a different design starting point entirely. It is what separates a backend built for humans from one built for agents. InsForge is built on that starting point.
InsForge is an open-source backend platform built for AI-assisted development. It provides database management, authentication, storage, serverless functions, and AI integrations, with APIs structured specifically for deterministic agent execution. Unlike backends that expose MCP as a layer on top of a human-facing platform, InsForge builds the MCP design into the backend itself.
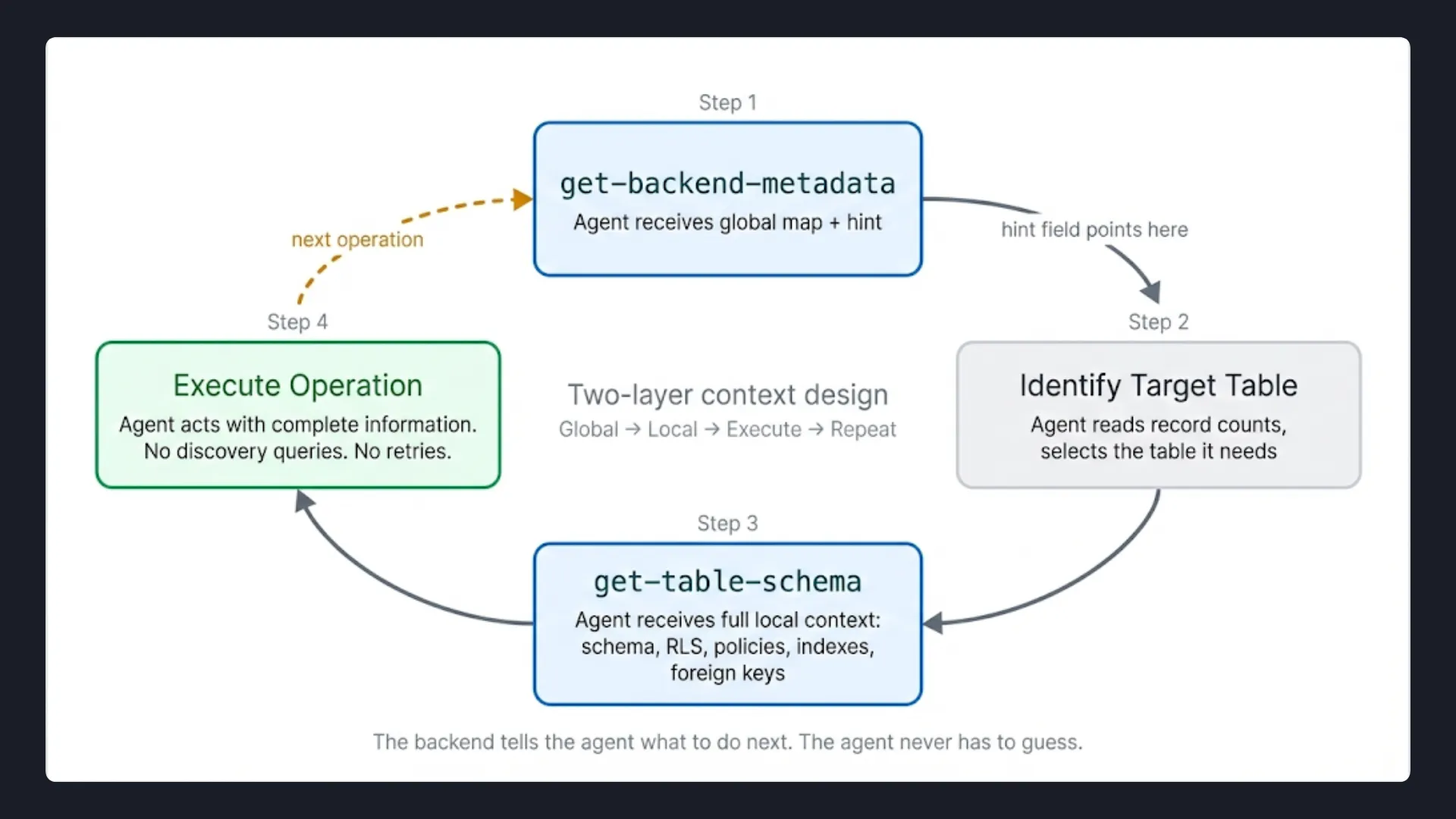
Its MCP server is built around two principles: hierarchical context and a live source of truth. Every tool call is designed so the agent gets exactly what it needs for the current step, with a clear signal pointing to what it needs next.
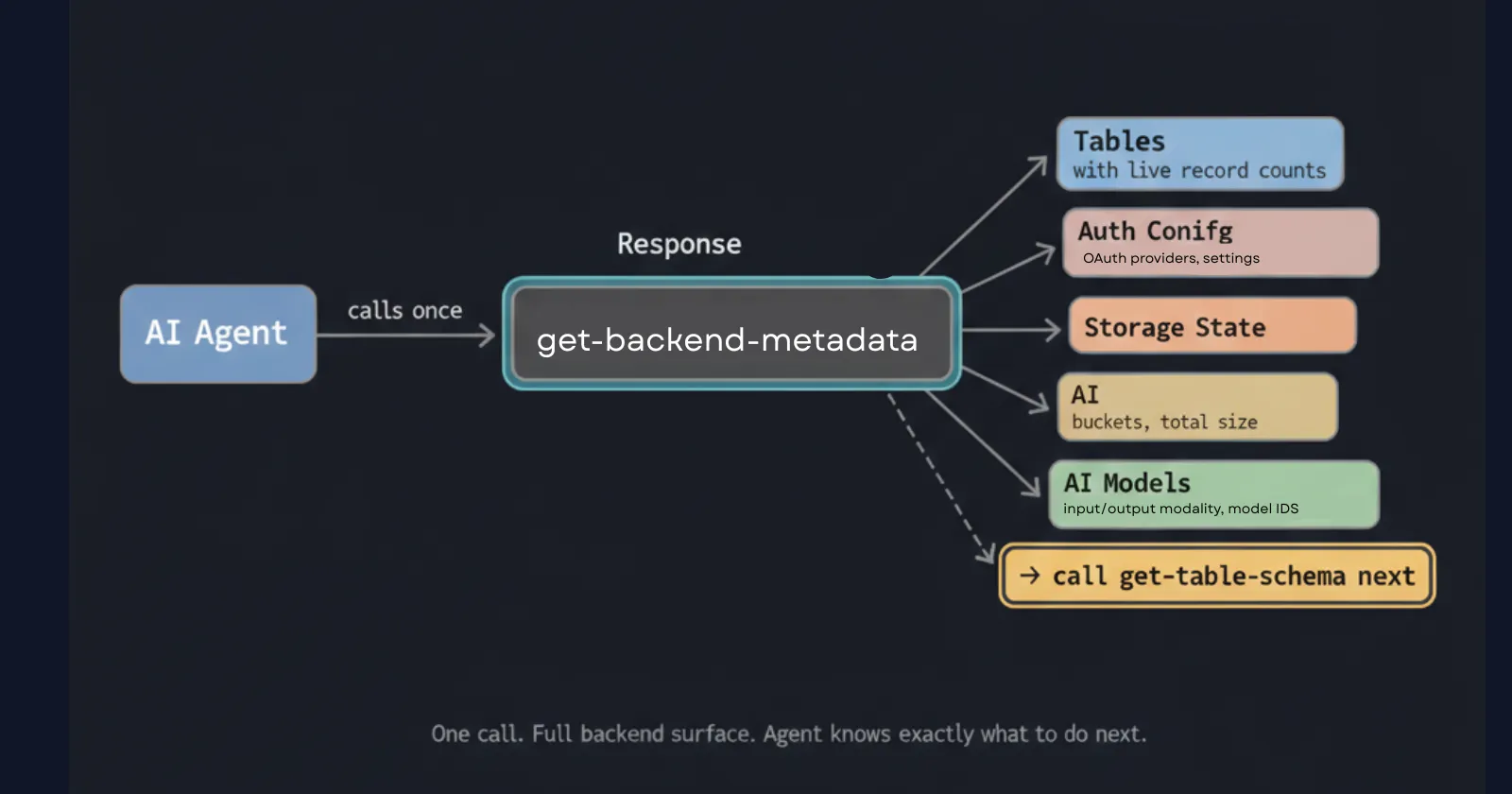
In practice, that means two layers: one that gives the agent a map of the entire backend, and one that gives it the full detail for exactly the table it is working on.
Layer 1: Global Context with get-backend-metadata
The first call an agent makes is get-backend-metadata. It returns the full backend surface in one response: every table with its live record count, auth configuration, storage buckets, AI model integrations, and a built-in hint that tells the agent exactly what tool to call next.
{
"auth": {
"oauths": [
{
"provider": "google",
"clientId": null,
"redirectUri": null,
"scopes": ["openid", "email", "profile"],
"useSharedKey": true
}
]
},
"database": {
"tables": [
{ "tableName": "users", "recordCount": 1 }
],
"hint": "To retrieve detailed schema information for a specific table, call the get-table-schema tool with the table name."
},
"storage": {
"buckets": [],
"totalSizeInGB": 0
},
"aiIntegration": {
"models": [
{
"inputModality": ["text", "image"],
"outputModality": ["text"],
"modelId": "anthropic/claude-sonnet-4.5"
}
]
},
"version": "1.0.0"
}
The recordCount field directly resolves Failure 2. Before writing a single query, the agent already knows there are 300,024 employee rows and 2,844,047 salary rows. It knows this is a many-to-one relationship. It knows COUNT(*) on a join will multiply rows. It writes COUNT(DISTINCT e.id) on the first attempt.
The hint field resolves the discovery loop problem. The agent does not have to guess what tool to call next or run exploratory queries to understand the backend topology. The response tells it directly.
Layer 2: Local Context with get-table-schema
Once the agent knows which table it needs to work with, it calls get-table-schema. This returns the full definition for that table in a single response.
{
"users": {
"schema": [
{ "columnName": "id", "dataType": "uuid", "isNullable": "NO", "columnDefault": null },
{ "columnName": "nickname", "dataType": "text", "isNullable": "YES", "columnDefault": null },
{ "columnName": "bio", "dataType": "text", "isNullable": "YES", "columnDefault": null },
{ "columnName": "created_at", "dataType": "timestamp with time zone", "isNullable": "YES", "columnDefault": "now()" },
{ "columnName": "updated_at", "dataType": "timestamp with time zone", "isNullable": "YES", "columnDefault": "now()" }
],
"indexes": [
{
"indexname": "users_pkey",
"indexdef": "CREATE UNIQUE INDEX users_pkey ON public.users USING btree (id)",
"isUnique": true,
"isPrimary": true
}
],
"foreignKeys": [
{
"constraintName": "users_id_fkey",
"columnName": "id",
"foreignTableName": "accounts",
"foreignColumnName": "id",
"deleteRule": "CASCADE",
"updateRule": "NO ACTION"
}
],
"rlsEnabled": true,
"policies": [
{
"policyname": "Enable read access for all users",
"cmd": "SELECT",
"roles": "{public}",
"qual": "true",
"withCheck": null
},
{
"policyname": "Disable delete for users",
"cmd": "DELETE",
"roles": "{authenticated}",
"qual": "false",
"withCheck": null
},
{
"policyname": "Enable update for users based on user_id",
"cmd": "UPDATE",
"roles": "{authenticated}",
"qual": "(uid() = id)",
"withCheck": "(uid() = id)"
},
{
"policyname": "Allow project_admin to update any user",
"cmd": "UPDATE",
"roles": "{project_admin}",
"qual": "true",
"withCheck": "true"
}
],
"triggers": []
}
}
This single response resolves Failure 3 completely. The agent sees rlsEnabled: true and the full policy definitions before it writes any SQL. It knows exactly which roles have access to which operations, what the qual conditions are, and what withCheck constraints apply. With full policy definitions and RLS state returned upfront, there is nothing left to discover and guess.
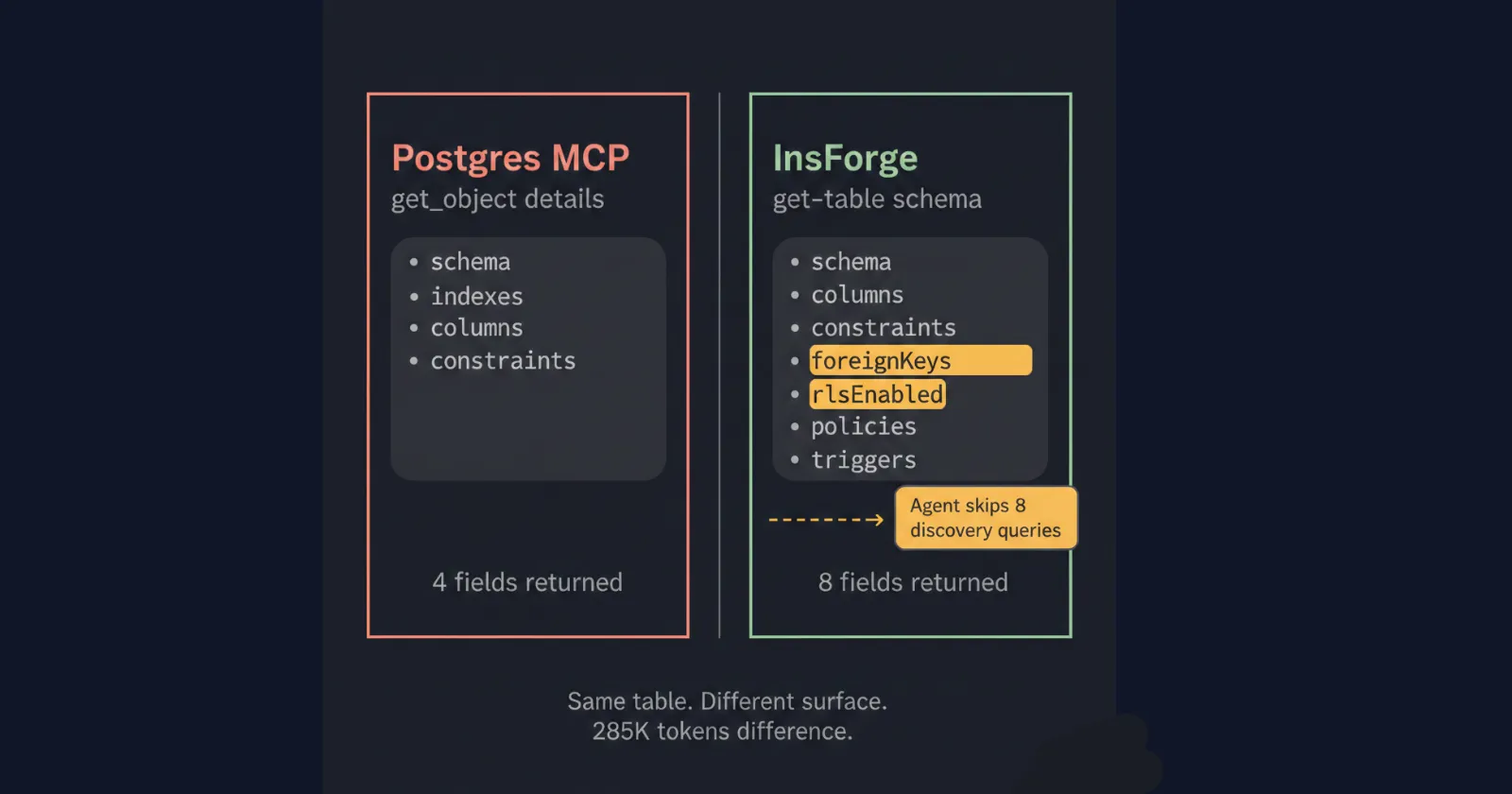
Compare this to what Postgres MCP returns for the same table:
{
"basic": { "schema": "public", "name": "users", "type": "table" },
"columns": [...],
"constraints": [...],
"indexes": [...]
}
No rlsEnabled field. No policies array. The agent has no way to know RLS exists on this table from this response alone. It proceeds, hits a permission error, and starts the retry loop that costs 285K extra tokens.
Why This Is an Architecture Decision, Not a Feature
The two-layer design is intentional.
get-backend-metadatais global context: it gives the agent a high-level map of the entire backend without overloading the context window.get-table-schemais local context: scoped, deep, and called only for the table the agent is actively working on.
This matters because of how context windows work in practice. Loading full schema details for every table upfront can consume 20K to 30K tokens of irrelevant information, pushing out logic the agent wrote earlier in the session. The hierarchical design keeps the context window clean while ensuring the agent always has what it needs for the current operation.
The hint field in get-backend-metadata is what connects the two layers. The agent does not have to reason about what to fetch next. The backend tells it. That is the difference between a backend that was retrofitted with MCP and one that was designed around how agents actually operate.
The context layer handles Failures 2 and 3. But a fully agent-native backend has to go further. Failures 1 and 4, non-deterministic operations and unguarded autonomous changes, are addressed at the platform level. InsForge's tool contracts return deterministic success and failure signals by design. Agent-initiated schema changes are logged, scoped, and reversible. The MCP layer and the platform contract layer work together.
The Numbers
The architecture described in the previous section is not a theoretical improvement. MCPMark makes it measurable.
InsForge, Supabase MCP, and Postgres MCP were all evaluated against the same 21 tasks using Anthropic Claude Sonnet 4.5 as the model. Each task was run 4 consecutive times.
The accuracy metric used is Pass⁴. A task counts as successful only if the agent completes it correctly in all four independent runs. Not once. Not three out of four. All four. This is what reliability actually looks like in production.
Case Study 1: Demographics Report
Task: employees__employee_demographics_report
Generate gender statistics, age group breakdowns, birth month distributions, and hiring year summaries from an HR database with an employee table (300,024 rows) and a salary table (2,844,047 rows).
| Backend | Success Rate | Tokens Used |
|---|---|---|
| InsForge | 4/4 (100%) | 207K |
| Supabase MCP | 3/4 (75%) | 204K |
| Postgres MCP | 2/4 (50%) | 220K |
Token usage is similar across all three. The failures are not a cost problem. They are a correctness problem caused entirely by missing record count information.
Neither Supabase MCP nor Postgres MCP tells the agent how many rows each table contains. The agent sees a join between two tables and writes the most natural query, which counts salary rows instead of employees. The output is 9.5 times too large. No error is thrown. The agent returns it as correct.
InsForge surfaces record counts in the first call, so the agent sees the row ratio before writing any SQL, knows COUNT(*) will multiply rows on this join, and writes COUNT(DISTINCT e.id) on the first attempt. 4/4 every time. The only difference is two fields in the first MCP response.
Case Study 2: RLS Setup
Task: security__rls_business_access
Implement Row Level Security policies across 5 tables on a social media platform: users, channels, posts, comments, channel_moderators.
| Backend | Success Rate | Tokens Used | Turns |
|---|---|---|---|
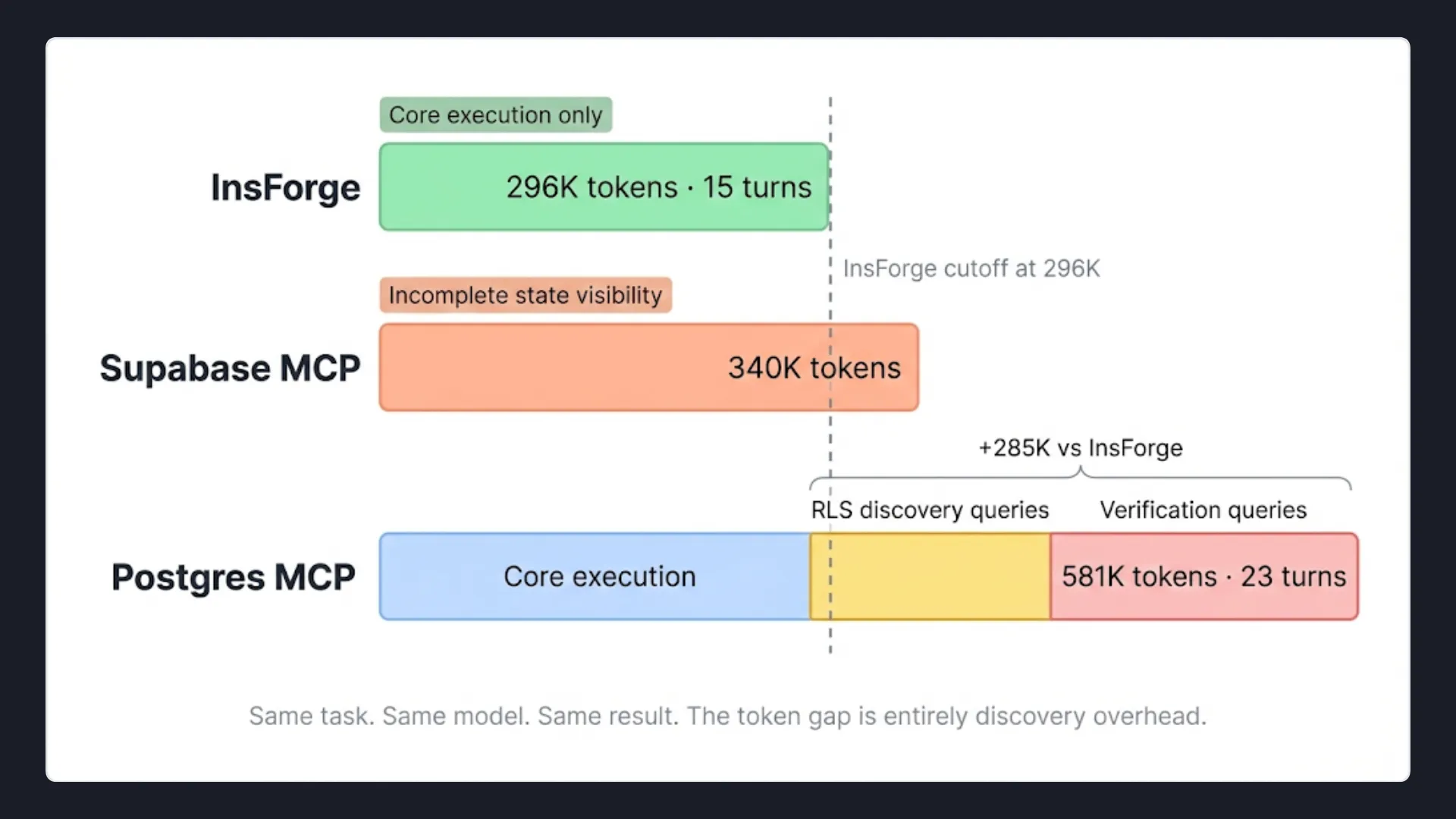
| InsForge | 4/4 (100%) | 296K | 15 |
| Supabase MCP | 1/4 (25%) | 340K | — |
| Postgres MCP | 4/4 (100%) | 581K | 23 |
InsForge and Postgres MCP both reach 100% accuracy. But Postgres MCP uses 581K tokens and 23 turns to get there. InsForge uses 296K tokens and 15 turns. The 285K token difference is not model behavior. It is the direct cost of the agent not knowing RLS state upfront.
Postgres MCP's execution path:
list_schemas → schema names only
list_objects → table names only
get_object_details × 5 → schema, no RLS status
execute_sql → query to check current RLS status
execute_sql × 8 → create functions, enable RLS, create policies
execute_sql × 4 → verification queries
InsForge's execution path:
get-instructions → learns InsForge workflow
get-backend-metadata → all 5 tables at a glance
get-table-schema × 5 → full schema with RLS status (parallel)
run-raw-sql × 6 → create functions, enable RLS, create policies
The Postgres agent runs extra queries to check RLS status and then verify the policies applied correctly because the information was never in the original response. InsForge skips both phases entirely because it was already there.
Supabase, without visibility into existing policies or RLS state, the agent could not reliably implement the required security model across 4 consecutive runs.
Aggregate Results
Across all 21 tasks:
| Metric | InsForge | Postgres MCP | Supabase MCP |
|---|---|---|---|
| Pass⁴ Accuracy | 47.6% | 38.1% | 28.6% |
| Avg Tokens Per Run | 8.2M | 10.4M | 11.6M |
| Avg Time Per Task | 150 seconds | 200+ seconds | 200+ seconds |
InsForge is 1.6x faster, uses 30% fewer tokens, and achieves 47.6% Pass⁴ accuracy against Postgres MCP's 38.1% and Supabase MCP's 28.6%.
The accuracy gap is significant given what Pass⁴ measures. Passing once is not the bar. The bar is passing the same complex backend operation 4 times in a row, without mistakes, without retries caused by missing context. At that bar, InsForge is the only backend that consistently clears it.
Closing
The future of agent-native development will not be defined by better models alone. It will be defined by what those models can see, the context they are given, the signals they receive, and the backend layer that determines both.
If this is the problem you are working on, InsForge is open source and we welcome contributions from the community.
Try InsForge
Quickstart guide here